
Caching is hard.
Unfortunately though, caching is quite important. Hosted caching & CDNs offer incredible powers that can provide amazing performance boosts, cost savings & downtime protection, essential for most modern sites with any serious volume of users.
Unfortunately, while there are strict standardsopens in a new tab for how caching is supposed to work with HTTP on the web, many cache providers do not quite follow these, instead giving their customers free reign over all kinds of invalid caching behaviour, and providing their own default configurations that often don't closely follow these standards to start with either.
There are many good reasons for this, but the main one is that CDNs are now doing dual service: providing performance improvements, and actively protecting upstream sites from DoS attacks and traffic spikes (similar problems - the key difference between a DoS attack and hitting #1 on Hacker News etc is intent, not impact). This conflicts with many of the standards, which prioritize correctness and predictability over this use case and, for example, expect clients to be able to unilaterally request that the cache be ignored.
Bunny.netopens in a new tab provides one of these CDNs, and like most they aggressively cache content beyond the limits of the standards, both to help protect upstream servers and to support advanced user use cases.
This has upsides, but in some edge cases can result in awkward bugs and break developer expectations.
In some more dramatic cases though, it can expose private user data, break applications & even leak auth credentials, and that's where this story gets serious. A few months ago, I ran into exactly that issue while testing out deployment options with Bunny.net, where I discovered that private HTTP responses intended for one authenticated user could be served to other users instead.
Spoiler: this is now fixed! That said, it's worth exploring where this went wrong, the many ways this can work right, and how CDNs solve issues like this in practice.
Caching vs HTTP Authorization
HTTP API authentication is typically implemented with an Authorization headeropens in a new tab sent in every request that looks something like Authorization: Bearer ABCDEF... where ABCDEF... is an authentication token linked to a specific account that you're provided elsewhere.
There are many good reasons why this pattern is so widespread despite the many possible ways to authenticate an API request over HTTP. One of the best is that middleboxes and other standard tools on the web know what an authorization header means and will handle it sensitively, for example not storing the header in log files, masking it in error reports, and definitely NEVER CACHING RESPONSES FROM AUTHENTICATED REQUESTS AND SERVING THEM TO OTHER USERS.
Ahem.
The HTTP caching standardopens in a new tab makes this last point abundantly clear:
A shared cache MUST NOT use a cached response to a request with an Authorization header field to satisfy any subsequent request unless a cache directive that allows such responses to be stored is present in the response.
If you ignore that, as Bunny.net did, this happens:
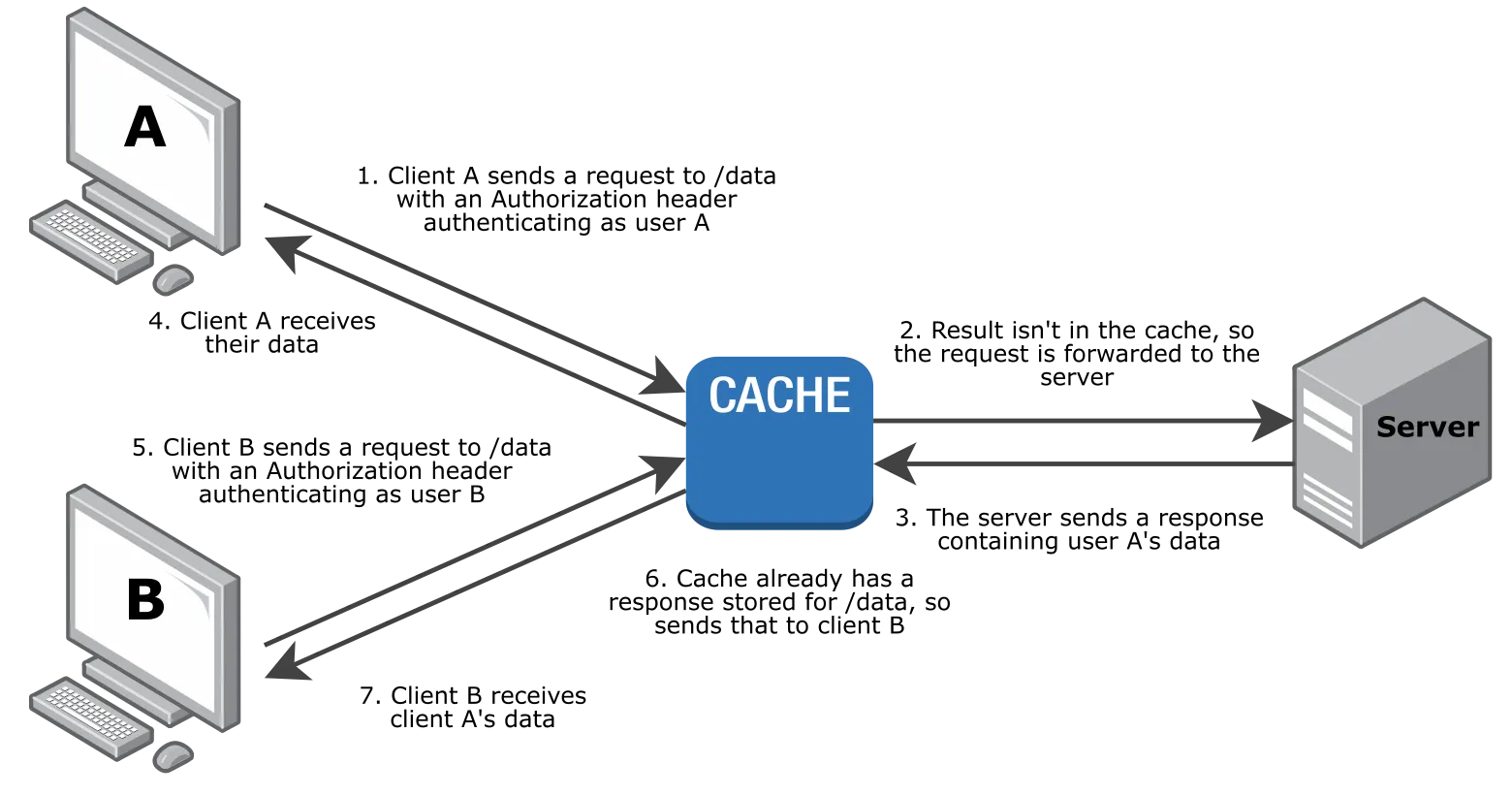
In this case, user A sends an authenticated request through the CDN's cache. Once this has passed through the CDN, the cache then stores it, using a cache key that doesn't include the authorization header (for simplicity, let's assume it just includes the URL).
Later user B sends another request. This could contain a different Authorization header, or no auth header at all. Regardless, user B isn't allowed to see user A's private content, but here they receive it anyway! The CDN finds a matching response in its cache, ignores the mismatched Authorization headers, and serves the private data straight back up to the wrong person.
This is what Bunny's CDN was doing, until recently. This is very bad indeed.
The response intended for user A sent instead to user B could contain all sorts of things user B should not see, and any of them could now be exposed. Private user data is the main problem (imagine the response to a /private-messages endpoint) but plausibly more problematic things like working API keys for the wrong account if a /list-api-keys or /generate-api-key response is cached (well-behaved APIs should do this with POST requests - not generally cached - and not expose a list of active keys, but much of of the internet is not well-behaved). If any such auth credentials are exposed, everything owned by user B is up for grabs.
Worse, this could be invisible. If CDNs are used only for media and heavier content, then APIs like /private-messages might not go through the cache (hiding the issue) while requests to APIs like /private-messages/attachments/123 would. Assuming that URL should return the same content for all users authorized to access the attachment, no normal user would ever see a problem, while in reality any user could request that private content and see it, allowing attackers to retrieve all private content from the CDN by just guessing or crawling through resource ids. Ouch.
(How much are CDNs used in front of APIs like this, rather than just for public static content? It's hard to say in general, but Cloudflare's stats say more than 50% of their handled requests in 2022 were API requestsopens in a new tab.)
Plugging the leak
For cache providers, there's a few ways to properly handle this issue:
Strip Authorization headers from all incoming requests by default
- This effectively returns unauthenticated responses for authenticated requests, which isn't great, but does solve the immediate security problem.
- This handles DoS and spike protection issues effectively (or at least, fully empowers the CDN to deal with them). Everything that can possibly come from the cache does so, and you can't skip it by just setting a random auth header.
- This is a reasonable response if your expectation is that the cache is purely for public static data, and nobody should be using it for authenticated requests in the first place.
- Can still allow users to configure custom behaviour on top of this, for cases where you do want authenticated data - you just force them to decide explicitly how to handle it.
Treat the Authorization header as part of the cache key, caching responses per user
- This ensures you never serve content to the wrong user while still providing great performance
- However, it can explode cache sizes, and still allows DoS attacks (just add any old auth header and you skip the cache).
- It also implies storing very sensitive data (authorization tokens) directly in your cache, which is generally not great for security.
Never cache responses for requests with an Authorization header
- This is the behaviour defined in the standard. These should never be cached unless they have explicit response headers marking them as cacheable.
- This neatly solves the issue, without exploding cache sizes or creating new security concerns.
- Anonymous requests can still be cached and returned to other anonymous users, but all authenticated traffic effectively skips the cache entirely.
- This does still leave you somewhat exposed to DoS attacks though, as anybody can add an auth header (valid or not) to skip the cache entirely, even when requesting public content.
Never cache responses for requests with an Authorization header, but do use existing cached responses if available
- If the Authorization header skips response caching but not request cache lookups (and isn't in the cache key) then successful anonymous responses may be served to authenticated requests when they're already in the cache.
- Note that's only for successful responses - if anonymous requests get a 401, that should never be cached (as far as I'm aware, all HTTP caches handle this correctly by default).
- This seriously limits the DoS exposure, as it ensures that endpoints serving any successful anonymous requests are always served from the cache.
- This is a bit weird & can cause unpredictable issues: your authenticated request might unexpectedly start receiving an anonymous-user response because of requests elsewhere. In most typical API designs though this won't happen (most endpoints are either authenticated or not) but weirdness is definitely possible.
Bear in mind that all of this is defining the defaults for authenticated requests. Of course individual responses can still define precisely how cacheable they are via Cache-Control and Vary response headers, and APIs with clear ideas of how fresh/cached responses can be should use that to manage CDN & client caching directly.
Personally, my strong preference would be to purely follow the standard, but that doesn't fit with the design of many CDN services, Bunny included, and so Bunny have implemented option #4. I strongly suspect that's for DoS protection reasons - my initial suggestion of following the spec approach was met with "Unfortunately, if we solve it the other way, by having it bypass the cache automatically, you open up a potentially worse vector of complete downtime and financial loss for any client".
Given those constraints, option #4 seems like a reasonable balance of security/caching. I can see how this is a challenging balance, and I do appreciate Bunny's work to quickly confirm this issue and then roll out a fix globally (released in late May).
Caching is hard
All this serves to neatly highlight once again that caching is a hard problem! There are a very wide variety of use cases and issues to handle, and the 'right' answer is often situation-specific, making specifying useful defaults for infrastructure providers very challenging.
So, what does everybody else do in this scenario? As far as I can tell:
-
Varnish bypasses the cache entirelyopens in a new tab (option #3) for all requests that use an Authorization header.
-
AWS Cloudfront strips the Authorization header by defaultopens in a new tab (option #1) but offers options to configure more advanced cases including adding it to the cache key (option #2). Notably, if you configure a policy that forwards the header without adding it to the cache key, Cloudflare will refuse to forward it at allopens in a new tab to avoid the original issue here.
-
Cloudflare workers bypass the cache for all requests with Authorizationopens in a new tab (option #3) even if
cacheEverythingis specifically enabled. -
Cloudflare CDN bypasses the cache for requests with Authorization headersopens in a new tab (option #3) unless either the server explicitly declares the response as cacheable via Cache-Control, or you disable Origin Cache-Controlopens in a new tab and manually mark it as cacheable yourself.
-
Google Cloud CDN blocks all caching of requests with Authorization headersopens in a new tab unless the response specifically declares itself as cacheable via Cache-Control.
(I haven't tested any of these myself - if you have more information, or more examples I should include here, do please get in touchopens in a new tab)
If you're using a CDN, and you're not sure you've configured this correctly, an easy way to test is to set up a URL you can GET through your CDN which logs the complete requests received and returns a 200 (or forward to a test service like webhook.siteopens in a new tab). Then you can make two requests with different Authorization headers, and if headers are stripped you'll see one request with no Authorization header, if the cache is bypassed you'll see both requests in full, or if authenticated requests are cached (the original security issue above) then you'll see just one request that does include its Authorization header.
You can even echo the Authorization header back in the response, to fully test this and see the security issue in action for yourself, but of course do be careful about doing that near any production traffic, as if this issue is present you'll be directly exposing authentication tokens between users.
Want to debug caching and API interactions up close? Try out HTTP Toolkitopens in a new tab now. Open-source one-click HTTP(S) interception & debugging for web, Android, terminals, Docker & more.
Suggest changes to this pageon GitHubopens in a new tab


